
Poetry, friends, is wild.
Since 2021 we've been working to transcribe and caption Voca, our online audiovisual archive of poetry recordings, and it has been a journey. (RIP my search history on this work-issued computer: just last week I found myself Googling the Sanskrit word for dog poop, and I had to stop for a moment to snicker about my life choices.)
But we've just hit a MAJOR milestone: we've completed all captions and transcripts. On every Voca recording.
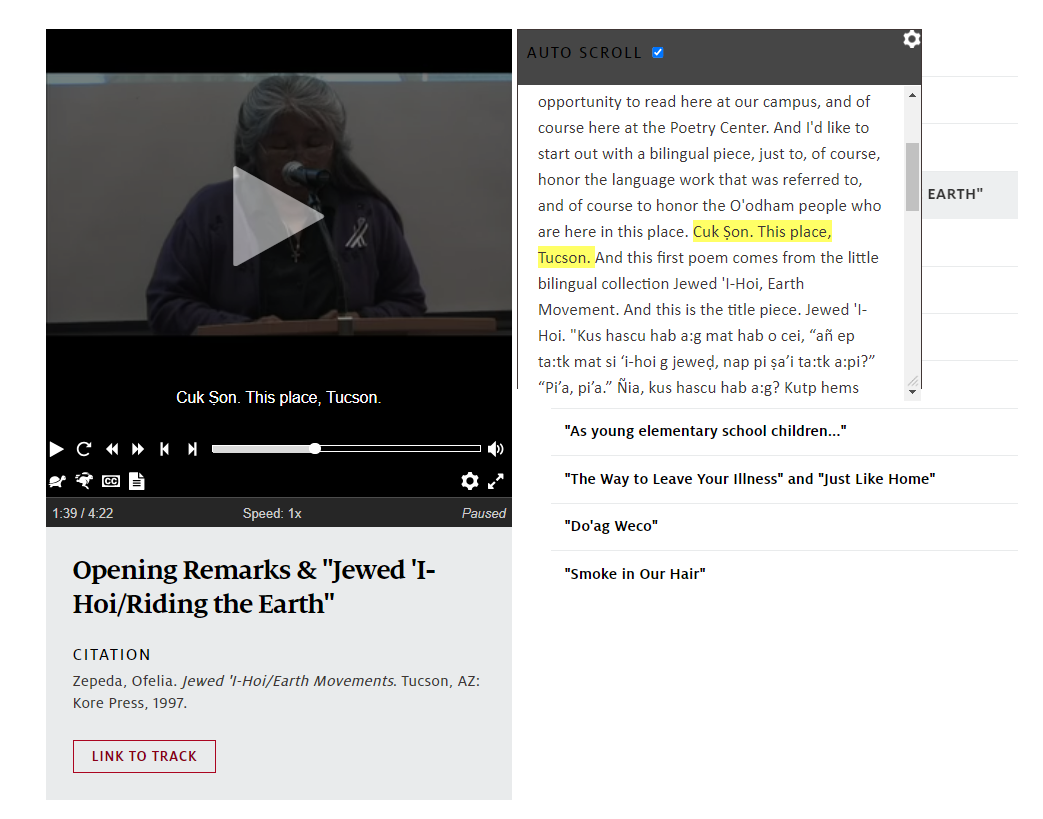
We finished captioning all our publicly accessible recordings last month, wrapping up our work on a Mellon Foundation-funded Public Knowledge grant to transcribe and caption the archive as a whole. The process involved sending media files to captioning vendors, checking the resulting transcriptions against poems in our library collections for accuracy, and uploading more than 12,000 caption files to individual tracks on Voca. As a very substantial side quest, we also collaborated with College of Humanities web developers to redesign the Voca site from the ground up to include caption and transcript functionality.
The results: Each recording you see on Voca now displays captions and transcripts, as well as sound and video.
As we end this voyage, we take stock of its wildnesses, including:
- Roughly six million words added to the archive in the form of plain-text .vtt files. Search engines index these files, which means that if you're looking for an especially hard-hitting phrase you remember from a Poetry Center reading, you can now find it quickly by entering that phrase into a general search engine. (Try Googling "Mortal pilgrims, I am Puss in Boots" with the quotation marks.)
- "Lost" recordings restored. As we worked on our caption files, we learned about the existence of missing tracks in some readings via context clues, and we were able to go back to our master recordings to find missing files and upload them to the archive. Archivist and Outreach Librarian Julie Swarstad Johnson even discovered, digitized, and uploaded an extra recording of the poet Ai reading in 1972 that had previously gone undigitized due to a dating error on the original media.
Olga Broumas, 1988
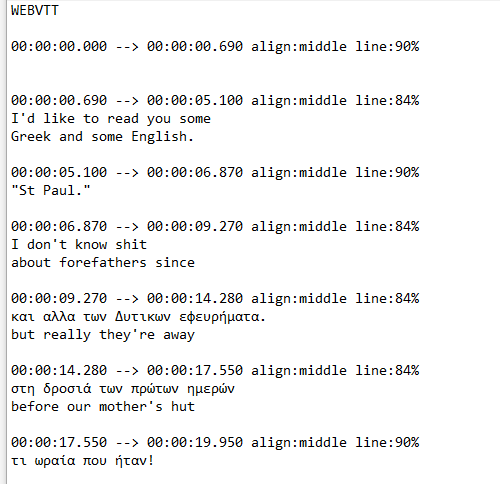
- At least 25 languages spoken on Voca. We discovered that we have A LOT of multilingual material in this archive, from the languages of the contemporary borderlands (Diné bizaad, O'odham, Español) to languages far from us in geography (日本語 ) and time (κλασική ελληνική). I leaned on Julie for Italian, docent Sylvia Chan for Chinese, and Event Coordinator Paola Valenzuela for Spanish; I called in native speaker transcribers via our captioning vendor 3Play Media for Hebrew, Czech, and Arabic; and I used every scrap of language training I've ever had (PRAISE BE to the Internet) to transcribe additional material in German, Japanese, French, Latin, and classical and modern Greek. I didn't ultimately figure out the dog poop question, though. That transcription just says [SANSKRIT], to my sorrow.
- New possibilities for digital humanities research created. Transcribing an audiovisual archive in this way opens its intellectual content not just to search engines, but to computational analyses more generally. I am extremely tempted to make a Voca concordance: what can we learn about the culture's underlying obsessions and values by examining word recurrences at poetry readings?
- First of its kind? The Poetry Center is among the first of our peers to attempt a comprehensive transcription and captioning project for a historical literary audiovisual archive; with this project's completion, Voca becomes one of the most searchable and most accessible archives of poetry recordings available online.
The Library team is very proud (and, tbh, a little giddy) to bring this project to completion. We hope you'll enjoy using the transcriptions on Voca: they represent tens of thousands of hours of devoted work from PC staff, student interns, professional transcribers, and COH web developers.
And if you're a Sanskrit scholar, let's talk. That missing word is bugging me.